
























Do you ever wonder how an email program knows what is spam or how Amazon can get a quick summary of all the customer reviews about a product? The answer isn’t magic. It is computer-based artificial intelligence AI text analysis — a very useful tool that is behind the scenes in a lot of the way we organize the Internet today.
Computer-based AI text analysis doesn’t simply look for words; instead, it understands the context, tone, and intent of those words. Just like people do when they read and interpret text. That is why companies have been able to quickly assess public opinion on a product based on social media postings, and why you are able to see multiple articles from the same topic grouped together by your news app with no effort required.
In fact, you are probably already using AI text analysis several dozen times every day. In this guide, I will explain how computers are learning to analyze and interpret the world as well as possible, using individual sentences and avoiding technical terms, so you can easily learn how computers read the world.
What Is AI Text Analysis? (It’s More Than Just a Keyword Search)
AI Text Analysis is primarily concerned with developing systems capable of reading and interpreting human language in all its complexity—its messiness, creativity, and unpredictability—how we actually write.
It is the technology that enables a computer system to move beyond simple word recognition to interpret the meaning, intent, and even emotions of those words.
Consider the differences between a simple search using keywords versus an actual understanding of the content. Searching a document for the word “unhappy”, will result in each occurrence of the word “unhappy”.
However, if you were searching for the phrase “this product was a huge disappointment” or “I am not satisfied at all”, regardless of whether either of the above phrases contained the word “unhappy”, an AI would understand that both of the above sentences expressed a negative sentiment (despite the lack of inclusion of the word “unhappy”). The AI understands the sentence’s context, not merely its characters.
The ability to analyze unstructured data—such as reviews, emails, social media posts, etc.—is considered a major advantage of AI. By analyzing context and intent, AI can do more than simply categorize data—it can also “read the room.”
Sentiment Analysis – How AI Understands Human Emotions from Text

Textual sentiment evaluation is the ability of computer systems to determine the emotional content of a given piece of text, most typically whether it is positive, negative, or neutral. Advanced systems may evaluate more complex emotions, including anger, joy, sadness, and fear. The field has been very successful at determining how people perceive specific items, services, organizations, and events.
There are two common techniques that are being employed to accomplish this task:
- Lexicon-based: Using lists of words classified as either positive or negative and using the results to determine the overall sentiment of the text.
- Machine Learning / Deep Learning: Training a model on previously annotated data (data that was previously labeled as positive/negative/neutral), so that the system can learn to recognize the patterns within the data and make determinations based upon new, unseen data.
Deep Learning systems have become very popular because they enable the development of highly contextualized models using word embeddings and transformer architectures, achieving greater accuracy than earlier methods.
Some of the most common uses of Sentiment Analysis include:
- Social Media monitoring of public reaction to marketing campaigns or events
- Analysis of product reviews to measure user satisfaction and/or dissatisfaction
- Sentiment tracking in Customer Support Tickets and Chat Logs
- Public Opinion measurement on policies, movies, or public figures
Common challenges associated with Sentiment Analysis include:
- Understanding Sarcasm and Irony (“Great, just what I needed…another delay.” is actually a negative statement.)
- Domain-specific Language (Slang, Jargon, Regional expressions, etc.)
- A single document containing both Positive and Negative Sentiment (“I like your phone…it’s fast, but I don’t like your battery…it’s terrible.”)
- Multilingual and Code-Mixed documents (Examples of Multilingual documents: Documents that contain both English and Local Languages.)
Reading the Room: How AI Instantly Knows if a Customer Is Happy or Angry
The fact that AI systems can understand context enables them to perform one of their most valuable functions — detecting emotions associated with words.
Imagine you have a large consumer products firm that has launched a new product, and thousands of social media comments are coming in about it. The number of comments could be overwhelming for an individual to review in real time.
To quickly determine whether the product launch is successful or unsuccessful, the company would use an artificial intelligence system trained to categorize text as Positive, Negative, or Neutral (emotional). This process is referred to as Sentiment Analysis.
AI systems are trained by reviewing millions of examples, associating terms such as “Love” and “Amazing” with positive sentiment, and “What a Disappointment” and “I am Returning this” with negative sentiment. AI systems will also identify neutral comments, such as simply asking about the store’s hours.
The advantages of sentiment analysis go well beyond a simple “thumbs up” or “thumbs down”. When a business analyzes a large volume of customer feedback (in this way), it can quickly identify issues raised. For example, if a restaurant chain noticed a rapid rise in customer complaints about “the food was cold” at one of its locations, it could address the issue before it further damaged its reputation and connect customer feedback to an operational change.
But understanding the overall sentiment is merely the beginning. To get a complete view, the AI has to determine which person(s), product(s), service(s), etc., people are actually talking about.
The Automatic Highlighter: How AI Finds Key People, Places, and Brands in Any Text
It is at this point that we see the emergence of the next skill of AI — as a super-intelligent, automated highlighting tool. Rather than simply scanning documents for emotional content, the AI can now quickly and automatically scan a document and locate all the key nouns (the “names”) — those of people, organizations, places, and products. This process of identifying and tagging key information is referred to as Named Entity Recognition (NER).
What really shows the potential of NER is when we are working with large volumes of text. For example, a business may want to know how many news articles have been written about its CEO. However, the business does not want to receive all news articles that include someone else with the same last name as the CEO.
The AI will find all references to the CEO’s name as a ‘Person’ within the context of their business and treat them as an ‘Organization.’ This precise keyword extraction from unstructured text data provides a business with a clear, transparent view of its public image.
After the AI identifies the sentiment associated with the extracted entities, it can uncover broader trends by uncovering underlying themes independent of human influence.
Named Entity Recognition (NER) – How AI Finds Key Information in Text
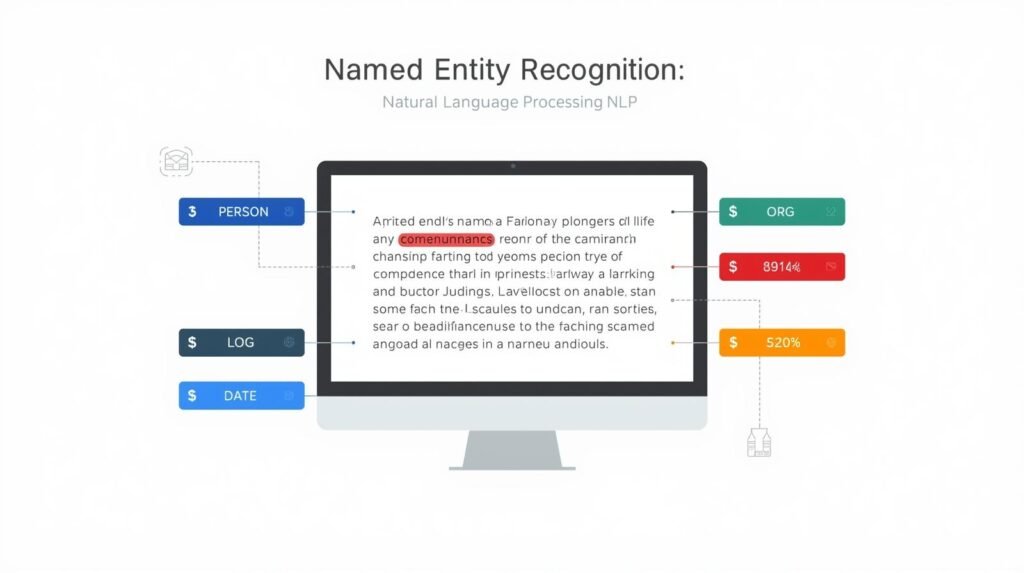
A system uses Named Entity Recognition (NER) to find and label “named entities” in unstructured text – for instance, people, organizations, places, time, products, and monetary values. Using the example “Apple introduced the iPhone in California in 2007,” the system identifies “Apple” as an organization, “iPhone” as a product, “California” as a location, and “2007” as a date.
NER transforms unstructured text into structured data and facilitates several applications, including:
- Information extraction from various forms of text (newspaper articles, legal documents, academic journals, etc.)
- Construction of knowledge graphs and structured databases
- Enhancement of information retrieval and recommendation systems (for example, identifying all references to a particular company or medication)
NER systems work by:
- Tokenizing the input text into individual words or subwords
- Extracting features from the tokens (including word shapes, surrounding context, and embeddings)
- Utilizing supervised machine learning or deep learning models (such as Conditional Random Fields (CRFs), Bidirectional Long Short-Term Memory – Conditional Random Fields (BiLSTM-CRF), or transformer-based architectures) to assign a type label (e.g., B-PER for the start of a person’s name, I-ORG for the middle of an organization name, O for a token that is not part of an entity) to each token.
Some challenges associated with NER are:
- Ambiguity (e.g., “Apple” can refer to both a corporation and a fruit)
- New or infrequent named entities (i.e., startup companies, newly approved medications, or new products)
- Multilingual and/or code-switched text
- Domain-specific NER (a model trained to recognize named entities within news articles will likely have difficulty when applied to other domains (e.g., medicine, law).
Text Classification – How AI Organizes and Understands Written Content
Classification of Text, or simply “Text Classification,” is the act of taking a piece of text and giving it one or more labels. A simple example is a spam email being classified as spam versus an email that is not spam.
Another example could be labeling topics in an article about Sports, Finance, Health, etc., or labeling an individual’s intent behind their message as a complaint, inquiry, or purchase request. The most frequently used and applicable NLP task is Text Classification.
Here is a general outline of the process of performing Text Classification:
- Gather and Label Data for Training (data with already assigned categories)
- Transform the text into a set of numbers that can be processed by a computer (using methods like TF-IDF vectorizing or word embedding)
- Train a Machine Learning or Deep Learning Model to perform the Classification Task (logistic regression, support vector machine, transformer-based models, etc.)
- Predict the Category Labels for New, Unseen Text using the Trained Model
Examples of Text Classification Tasks are:
- Spam Filtering Emails
- Automatically Tagging Support Tickets (Billing Issue, Technical Issue, Sales Inquiry, etc.)
- Categorizing News Articles (Politics, Tech, Sports, etc.)
- Detecting Intent Behind Messages to Chatbots (Status of Order, Cancel Request, Feedback, etc.)
Metrics commonly used to evaluate the quality of the results of a Text Classification Model are:
- Average Accuracy of Predictions: How accurate were all of the predictions made by the model?
- Precision of Predictions: Of all of the messages that the model predicts will fall into a particular category, how many actually do?
- Recall of Correctly Classified Messages: Of all of the messages that should have been classified into a particular category, how many were the model able to correctly classify?
- F1-Score: The harmonic mean of Precision and Recall. This metric gives equal weight to the two other metrics and provides a balanced view of both.
Finding Hidden Themes: How AI Can Sort a Mountain of Data Into Neat Piles
The largest opportunity for discovering themes you never thought to look for is also AI’s greatest strength. Take a thousand pages of customer surveys – your only objective is to discover what customers are discussing. The best way to accomplish this task is to use AI as an automated sorter: read all the surveys and group them into thematic piles based on the AI’s logical thematic groupings.
Topic modeling is how this is done; by identifying which words appear together, the AI determines there are “delivery issues” when it sees the words “late,” “damaged,” “shipping cost” together, then groups those reviews into a “delivery issues” pile; at the same time, the AI may identify other responses using “easy,” “checkout,” “website” and places those into another thematic pile called “positive online experience”.
This model does not simply organize what you know. Rather, it will reveal your “unknown unknowns.” For example, while a business may believe its most serious issue lies with price, topic modeling can identify a large, previously untracked theme: customers complaining about product instructions that are confusing (a problem no one was monitoring). Thus, it allows businesses to take an objective look at their customers’ real concerns.
Too Long; Didn’t Read? How AI Creates Instant Summaries
Sorting through the details in a document is much better than sorting through random, unorganized data; however, there are times when you simply need to know the facts quickly. It is at this point that one of the AI’s most practical capabilities comes into play.
Automated Content Summarization — which creates an instantly readable summary from lengthy and complex documents — allows for rapid generation of summaries (a short paragraph) of long articles or documents that have numerous pages. This process, in effect, functions like an extremely rapid research assistant.
An AI tool may read a 20-page article, identify its main points and supporting evidence, and generate a short paragraph summarizing the article in seconds.
While the ultimate objective is to assist in managing vast amounts of data (by reducing its volume), it does so by providing brief, easily understandable excerpts from longer texts (e.g., news articles, legal documents). The ability to rapidly decide whether to evaluate a particular dataset depends on the AI’s language understanding.
How Does an AI “Learn” to Read? A Peek Behind the Curtain
Unlike humans, who do not use “flash cards” as an instructional method when learning to read, a machine or artificial intelligence (AI) learns to read through examples, many millions of them. To give you an idea of this type of learning, imagine taking a brand-new employee and giving them two enormous bins of your existing customer review feedback – one bin is labeled as “positive,” and the other is labeled as “negative.”
The only task for this new employee would be to review all the reviews in both bins and identify similarities between those in the “positive” and “negative” bins. After some time, the new employee would eventually recognize that phrases such as “I love it” typically belong in the “positive” bin, whereas “disappointed” typically belongs in the “negative” bin.
The heart of text analysis is identifying statistical patterns in language use within large amounts of labeled text (training data) to create a complex map of mathematically connected language items and their corresponding outcomes. To identify sentiment in text, for instance, an AI will be given many examples, such as “you get a refund”, which has been previously identified as a customer service issue, and “Congratulations, you got your job!!!” as a positive announcement.
So fundamentally, all skills we have explored up to now, determining sentiment, and summarizing articles are based upon the same process of creating the above-described connection between the labeled patterns and applying them to new, never-before-seen text.
Where You Already Use AI Text Analysis Every Single Day
You may view this technology as distant and complicated, but you have probably already used it many times today without realizing it. This technology is referred to as artificial intelligence (AI) text analysis. Many of your digital experiences are powered by the unseen workings of AI text analysis.
Recognize any of these?
Your Email Inbox: How does your email inbox sort incoming emails into categories such as Primary, Promotions, and Spam? That’s all because an AI read the message’s content to determine its intent and filed it accordingly.
Customer Reviews: How does Amazon summarize customer reviews? An AI reviewed thousands of customer reviews and determined which theme or topic each reviewer discussed most often. Examples include long battery life.
Your Search Bar: What happens when you enter the phrase best pizza places near me in your search bar? Your search engine recognizes that you want to find local restaurants, not just the words you entered in your search bar.
Chat Bots: A chatbot that responds to your inquiry about shipping status on a retailer’s website uses text analysis to recognize that you want to know the status of your shipment.
Curious? How You Can Try AI Text Analysis in 5 Minutes (No Code Needed)
While reading articles about AI is exciting, I believe it would be even more thrilling to test out your own ideas with AI. Fortunately, many organizations that develop and use AI make available (at no cost) demonstration tools they have created to the public. These demonstrations are essentially playgrounds where users can enter text into a box and watch in real time as an AI analyzes and understands it.
Here’s a simple example of how you might test this type of demo tool: Look up a “text analysis demo tool” using an internet search engine. Select a demonstration tool that interests you, and then perform the following exercise. Simply copy and paste a positive, 5-star review of a product into the demo tool, and then observe as the AI identifies the review as being “positive.
Next, copy and paste a negative review from a customer who had a bad experience with a product into the demo tool. The AI will identify negative sentiment and, most likely, also provide details on why the customer was unhappy, such as shipping issues or poor quality. In a single click, you’ve leveraged the core technology that enables large multinational corporations to extract insights from hundreds of thousands of customer opinions and comments.
Rather than an impressive trick, this is your first view of the engine behind how we understand the digital world, as in how it takes in mountains of data, then organizes, summarizes, and interprets it.
Natural Language Processing (NLP) – How Machines Understand Our Words
NLP is an area of research in artificial intelligence that enables computers to interpret, process, and generate human language. The NLP field combines linguistic principles, machine learning, and computer science to enable computers to read and write text and speech. It can be applied in a number of ways, such as summarizing articles, answering questions, translating languages, and evaluating customer comments.
Many common applications that you utilize on a daily basis rely upon NLP — including but not limited to search engines, chatbots, voice assistant systems, spam filters, and translation apps. For organizations, NLP converts unstructured text (tickets, emails, review comments, reports) into structured insights, including identifying which complaints are most commonly experienced by consumers and extracting relevant information from lengthy documents. In addition, NLP reduces manual reading time and enables faster decision-making based on available data.
The common steps involved in developing an NLP pipeline include:
- Text Cleaning (the removal of “noise” within text — i.e., unnecessary whitespace, HTML tags, etc.)
- Tokenization (breaking down text into words or sub-words)
- Normalization (i.e., converting all letters to lower case, removing the suffixes from words, etc.)
- Feature Extraction (converting text into numeric values — e.g., word embeddings)
- Modeling (utilizing machine learning or deep learning techniques to accomplish tasks such as classification, sentiment analysis, etc.)
- Evaluation (assessing the performance of your model utilizing accuracy, F1 score, etc.)
A New Lens for a Digital World
What was previously thought to be “digital magic” is now something that can be identified and named. You have drawn back the curtains on AI text analysis, making an abstract concept of “AI” into a collection of identifiable skills. No longer are the abilities to understand emotions, identify the most important points in large amounts of text, or break down large amounts of text into identifiable themes mysterious.
Now that you have this lens for seeing Text Analytics tools everywhere, try to find them over the next 7 days. Take notice of how a streaming service suggests a movie based on a reviewer’s sentiment toward a film, or how a news app identifies articles related to specific topics. Simply taking the time to notice where these tools are located will help solidify your new knowledge by relating what you’ve learned to the daily navigation of your own digital world.
This is more than a trivia exercise; it is an example of Digital Literacy. Learning the fundamental principles of Natural Language Processing (NLP) will make you a more knowledgeable and informed digital citizen. As such, you are now an informed observer of how the never-ending stream of text online is being processed, categorized, and utilized to create your experience. You do not simply see the discussion; you also see the programming and coding that went into creating it.











{kind=link}