













Machine Learning (ML) is a subfield of artificial intelligence (AI) that enables a computer to “learn” from experience rather than being explicitly programmed. Essentially, ML takes an algorithm or mathematical formula, runs it on a large dataset, looks for patterns within that dataset, and then uses those patterns to predict what would occur with a similar but different dataset.
The fact that machine learning can handle numerous problems and domains and process a variety of data sets clearly shows how flexible it is. Since machine learning is such a versatile tool and so important to the ongoing improvement of AI, it plays a significant role in AI development. Additionally, the field of machine learning is continually evolving; therefore, we can confidently say that it is becoming a key component of the overall AI community.
There are various forms of machine learning. Some examples include supervised learning, unsupervised learning, and reinforcement learning. Each form of machine learning employs a unique methodology for developing and training models; thus, researchers and practitioners can choose which method to apply to the problem they want to solve.
One of the greatest benefits of machine learning is that, once trained on data, algorithms can continue to improve, increasing both their accuracy and performance as they receive additional data. This continued ability to improve and enhance (or “adapt”) upon itself is one of the reasons why machine learning is so adaptable and effective in all areas of industry, including banking/financial services (i.e., assisting in determining risk) and healthcare (i.e., helping in diagnosing diseases and providing personalized treatment options for patients).
#Algorithms in AI: A Beginner’s Guide to Core Concepts
Summary
Machine Learning is a broad field that enables computers to identify patterns in data using supervised, unsupervised, and reinforcement learning approaches, while Deep Learning is a specific subfield of machine learning in which the learning process relies on artificial neural networks (ANNs). ANNs typically consist of multiple layers that automatically learn and extract relevant features from large, complex databases. These two methods share commonalities in their approach, but there are significant differences between them.
Some of the key differences include how much data is necessary to train the model, what kind of hardware it will run on, how much preprocessing/feature engineering has to occur prior to training a model, and how long it takes to train a model and how long it takes to infer output from a trained model.
In terms of data, Machine Learning does not require much data at all, uses expert-engineered features, and trains and infers outputs rapidly. On the other hand, Deep Learning requires large amounts of data, may use Graphics Processing Units (GPUs), may trade off longer training times for faster inference times, and generally outperforms Machine Learning for tasks involving unstructured data like images, speech recognition, natural language processing, and other high complexity tasks where automatic feature extraction would be beneficial.
Therefore, select Machine Learning if you need a low-cost, interpretable solution that leverages your domain knowledge. Select Deep Learning if your project involves one of the aforementioned high-complexity tasks: vision, speech recognition, NLP, etc., and you wish to utilize deep learning’s automatic feature extraction capabilities.

The first step in supervised learning (machine learning), is that a computer program learns how to perform a task by being trained on labeled data. What makes this form of training unique is that each set of input data provided to the model is associated with the correct output value. This means that the computer program learns to associate input data with output data and, therefore, can produce an answer when presented with new input data.
After the program has completed its supervised learning phase, it will have learned enough about the problem space to begin producing results for new input data that was not part of its original dataset. The supervised learning method is often referred to as “example-based” because it continually adjusts its internal parameters through trial and error, refining its ability to provide accurate answers over time. With each iteration, the model will become better at predicting the outcome of input data than it did in the past.
There are numerous ways in which supervised learning has been successfully implemented in real-world applications. For example, spam filters use supervised learning algorithms to categorize incoming emails as spam or non-spam. These programs enable users to quickly scan their inboxes to remove unwanted e-mail messages. Another application of supervised learning is image classification.
By applying a supervised learning algorithm to an image of objects, the model can identify and label each object. For example, if you were to show the model a picture of a cat, it would be able to label the object in the image as a “cat.” If you were to show a picture of a dog, the model would similarly label the object in the image as a “dog.”
One key feature of supervised learning is its ability to draw upon prior experiences to make educated guesses about new data sets. Because supervised learning models can learn generalized rules from patterns in prior data, they are well-suited for predictive analytics applications. Predictive analytics are used by many organizations to forecast future trends and events based upon historical data. Organizations can use predictive analytics to gain insights into potential future scenarios, allowing them to plan and prepare accordingly.
What is Deep Learning?
Deep learning is a type of Machine Learning; it uses Neural Networks with at least 3 layers. The intention of the deep learning model is to simulate how the human brain operates so it can “learn” from vast amounts of data. While many Machine Learning Models require manual extraction of data features, some can automatically discover these features and complex relationships within the data.
The success of deep learning models when dealing with large volumes of complex data (i.e., images, audio) can largely be attributed to their ability to process information at several levels of abstraction (hierarchical).
Hierarchical processing allows Deep Learning Models to find both high-level and low-level properties of data. Without such powerful models, much of the information in the data may not be found using less capable algorithms.
Neural Networks: The Backbone of Deep Learning
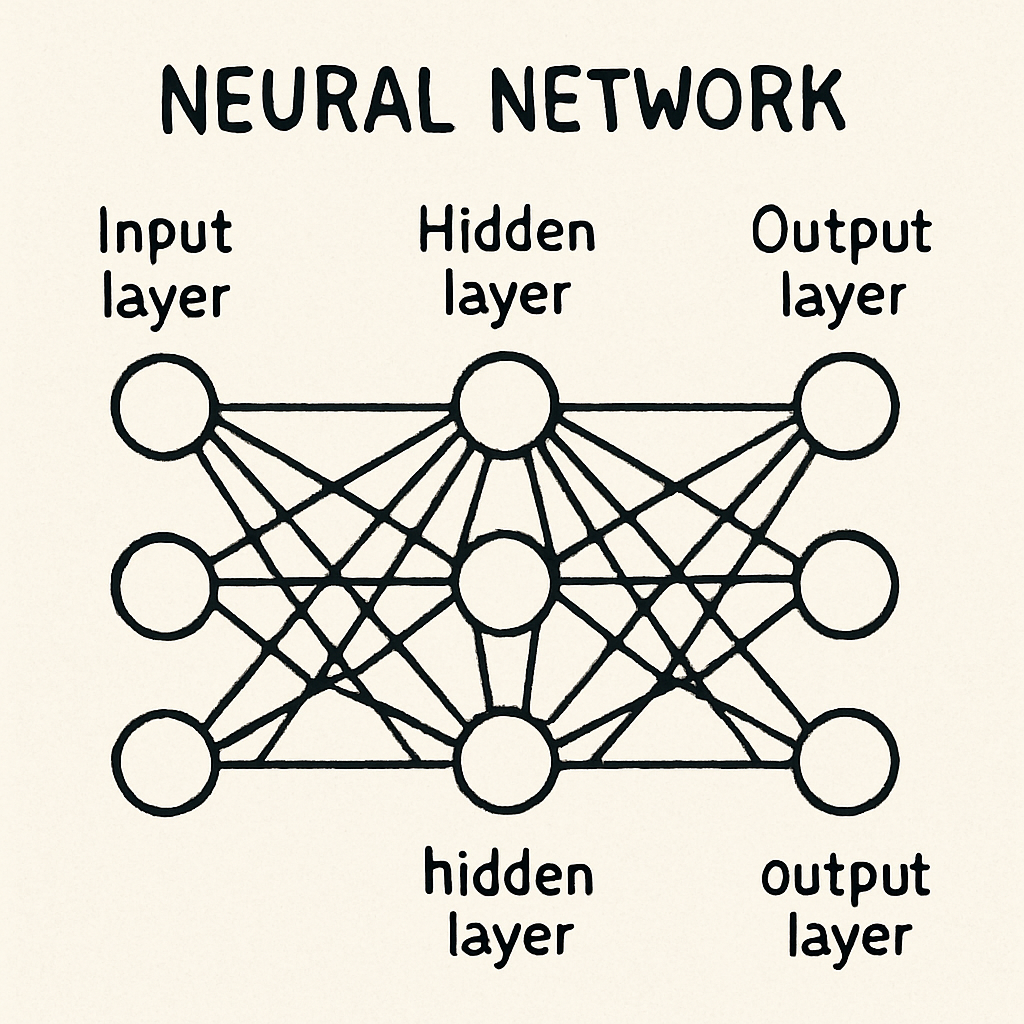
Neural Networks Architecture
| Network Type | Use Case | Strength |
|---|---|---|
| CNN | Image recognition | Feature extraction |
| RNN | Sequential data | Time-series analysis |
| LSTM | Long sequences | Better memory |
| GAN | Data generation | Realistic outputs |
Source:
Deep learning identifies the characteristics it needs to classify or predict items from raw data, as opposed to other machine learning methodologies that rely on manual extraction of those characteristics. As such, Deep learning uses backpropagation to adjust the weights of its Neural Network so that it makes better classifications/predictions, thereby enabling it to achieve strong results with unstructured data (such as images or audio) where a manual approach to feature engineering would be difficult, if not impossible.

A typical neural network has many layers of nodes. The input layer of nodes receives data into the model and passes it to one or more hidden layers. Each node in the output layer represent the result of the classification or prediction. These connections allow the model to learn and develop representations of the non-linear relationships among all the variables in the data.
Key Differences Between Machine Learning and Deep Learning
There are significant distinctions between deep learning and machine learning:
Machine Learning vs Deep Learning
| Feature | Machine Learning | Deep Learning |
|---|---|---|
| Data Requirement | Moderate | Very High |
| Algorithms | Regression, Trees | Neural Networks |
| Feature Engineering | Manual | Automatic |
| Hardware | CPu-based | GPU/TPU required |
| Accuracy | Good | Very high (complex tasks) |
Source:
Data Dependency
A small or medium-sized dataset can yield excellent results for machine learning. In addition, Machine Learning can make informed decisions using relatively limited data. Most machine learning models are engineered using features designed by humans. Therefore, the use of feature engineering allows machine learning to excel when domain knowledge exists, enabling enhancements to model performance. As a result, this process provides more reliable results across numerous applications.
To operate effectively, Deep Learning models require substantially more data than Shallow Models. Deep Learning models rely upon Artificial Neural Networks (ANN). ANNs rely on access to a large amount of data to learn and discover important attributes within a dataset. Therefore, the volume of training data can affect the operation of a Deep Learning Model.
Therefore, it makes sense to consider using Deep Learning when a considerable amount of data is readily accessible for a specific problem. For example, Social Media Analysis and Genomics are two areas where sufficient data exist to support the successful operation of Deep Learning and provide highly accurate responses.
Hardware Requirements
Deep Learning Models are very resource-intensive, requiring substantial computing power. This is provided by Graphics Processors, commonly referred to as “Graphics Processing Units,” or simply “GPUs.” Due to the amount of data required to develop Deep Learning Models and the complex way this data flows through a neural network (which includes multiple layers of connected nodes), as well as the computations performed at each level, GPUs can process large amounts of data simultaneously.
Thusly, because Deep Learning Models include vast quantities of mathematical computations, the fact that GPUs can be utilized in tandem to process data on a massive scale (simultaneously), enables these processors to provide the optimal solution to execute applications utilizing Deep Learning Algorithms. GPU design allows users to process data sets simultaneously, thereby reducing training times for applications and increasing performance.
Machine Learning Applications utilize substantially less powerful hardware than Deep Learning Algorithms. Consequently, most Machine Learning Applications operate proficiently using significantly less powerful hardware. Additionally, unlike in Deep Learning Applications, there is no need to use graphics processing units (GPUs) when implementing machine learning algorithms. As a direct result of this, machine learning is becoming a viable and cost-effective alternative for organizations and researchers without access to high-powered computers. This accessibility is the primary factor why machine learning is being applied in so many different areas.
Although machine learning requires much less high-performance hardware compared to deep learning to quickly train models and successfully deploy them, regardless of how well-designed the machine learning algorithm may be, the hardware on which it is implemented will greatly impact both the speed and efficiency of model development and deployment. Therefore, having an appropriate computational infrastructure will positively influence the overall performance of the machine learning model.
Feature Engineering
Feature Engineering is one of the key elements of the Machine Learning Process. Domain Experts use their domain and industry expertise to create or choose Features which enhance the predictive power and efficiency of the Machine Learning Model.
To create good Features, sufficient domain knowledge and experience are needed so that the selected Features capture sufficient information about the data for the Model to predict accurately. However, because Feature Engineering is done manually, it can take a long time; yet by embedding domain knowledge into the Model via Feature Engineering, the Model can yield better results than if it were developed without Feature Engineering.
Many current machine learning applications rely on manual feature engineering. Deep learning provides a unique alternative to feature engineering that does not involve manipulating the features. For example, deep learning models can extract relevant features from raw data. Therefore, using deep learning to generate features makes it much easier to develop models.
Automatic feature generation is especially useful in complex domains (e.g., image and speech recognition) that require significant domain-specific knowledge. In addition to assisting developers in building models, the automated feature learning inherent in deep learning has enabled researchers and developers to investigate numerous new opportunities and advancements in many other application fields involving unstructured data.
#Supervised vs Unsupervised Learning: The Key Differences You Must Know
Feature Engineering vs Automatic Learning
| Aspect | Machine Learning | Deep Learning |
|---|---|---|
| Feature Creation | Manual | Automatic |
| Time Reguired | High | Lower |
| Expertise Needed | Domain knowledge | Less manual effort |
| Performance | Depends on features | Learns complex patterns |
Source:
Execution Time
There are a variety of ways machine learning differs from deep learning, but they do share one similarity: models developed using either method will train faster than those developed using deep learning. Most deep learning architectures are highly complex, with thousands of parameters. This leads to greater computational requirements, resulting in longer training times for these models.
In addition, because the process of training these models is iterative and requires that all data be processed prior to training, the overall time required to complete their training is longer than that associated with machine learning.
Although deep learning models may require longer periods to train than machine learning models, they can quickly evaluate additional inputted data and provide predictions after being trained. For instance, if we consider some examples of how much quicker deep learning models can produce results than machine learning models; for example in situations requiring real-time analysis (such as live video feeds), or operating autonomously within self-driving vehicles.
Therefore, in environments requiring immediate, accurate decision-making the fast and accurate predictive abilities of deep learning may offer a competitive advantage. Practitioners should therefore determine which approach would benefit them more by comparing the two; specifically weighing the advantages of training speed against the advantages of prediction speeds.
Execution Time & Hardware Comparison
| Aspect | Machine Learning | Deep Learning |
|---|---|---|
| Training Time | Faster | Slower |
| Hardware | CPU | GPU/TPU |
| Cost | Lower | Higher |
| Scalability | Moderate | High |
Applications of Machine Learning and Deep Learning
Machine Learning and Deep Learning are widely used across industries and sectors and have numerous applications, including in Finance.
AI Adoption & Performance Statistics
| Metric | Insight |
|---|---|
| AI adoption globally | 60% + organizations |
| Deep learning accuracy (vision tasks) | 95%+ |
| Data used in DL models | TB-scale datasets |
| ML used in enterprises | Majority use cases |
| AI market growth | 30% + annually |
Source:
Machine Learning Applications
Finance is a field where machine learning is of great importance for Fraud Detection, Risk Management, and Stock Price Forecasting. Organizations use machine learning models to assess their customers’ or clients’ transactions to determine whether fraud was committed. Additionally, organizations have become more effective at assessing a borrower’s creditworthiness, enabling them to make more informed lending decisions.
Lastly, by analyzing large amounts of financial data, Machine Learning allows investors/companies to gain insight into market trends, enabling them to forecast potential changes in the stock market.
Machine Learning has many uses in the medical field, such as predicting diseases and creating personalized treatment plans. With Machine Learning, Medical Professionals will be able to review large amounts of patient data using advanced algorithms and therefore predict patients’ future health issues before they occur and intervene early to positively affect overall health.
Additionally, Machine Learning will help a medical professional find the best course of treatment for a particular individual by reviewing their specific needs, ensuring the individual gets the greatest benefit from the care received.
In addition to other areas within Marketing, Machine Learning has been used in Customer Segmentation, Recommendation Systems, and Sentiment Analysis. Machine Learning has enabled businesses to analyze enormous amounts of information about their consumers and use it to help business owners understand the buying habits and behavior of their target market, resulting in more effective targeting of their customer base.
Once a company has segmented its customer base, it can develop focused marketing campaigns that are designed to appeal to each segment. Also, Machine Learning has enabled the creation of recommendation systems that recommend products to consumers based upon their purchasing history and product preference patterns; this will increase customer interaction with the products. Lastly, Machine Learning-based sentiment analysis tools allow companies to gather both positive and negative customer comments about their products and services, helping them better understand how customers perceive them.
Real-World Example: ML vs DL
| Example | Email Spam Detection vs Image Recognition |
|---|---|
| Machine Learning: Classifies emails as spam/not spam using structured data | |
| Deep Learning: Identifies objects in images using CNNs | |
| Result | ML works well for structured tasks |
| DL excels in complex data (images, audio, video) |
Source:
Deep Learning Applications
Deep learning models have shown tremendous potential in recognizing patterns in images and videos, making them an attractive approach for many applications that require accurate image or video identification (e.g., Autonomous Vehicle Navigation, Object Detection, and Individual Detection). An additional example is facial recognition, where deep learning models take photographs/images/videos, detect faces in them, and then match the face to a person’s identity.
Deep learning models called Object Detection Models can analyze and identify objects in a photograph/image and even determine their locations and sizes.
NLP (Natural Language Processing) represents several different areas, including text-based sentiment analysis, chatbots, and language translation. Advances in Deep Learning technology have allowed computers to better comprehend and produce human generated language. As a result of continued advances in our understanding of and ability to create human-generated language through Deep Learning, we will see increasingly complex applications of conversational AI (chatbots), instant translators, and sentiment analysis tools.
In addition, advancements in understanding speech and developing techniques to use it for interaction with machines using Deep Learning have created numerous opportunities for Audio Recognition applications (Speech-to-text Systems, Virtual Assistants, etc.).
The future of Interactive Voice-Based Technologies depends on the ability to effectively translate spoken language into actions taken by devices. Developers of these technologies will use Deep Learning techniques to create applications that not only recognize and translate spoken words but also interact with users in a more “natural” manner, providing instant responses to User commands and queries.
Conclusion
Understanding the difference between machine learning and deep learning is very important for deciding whether either is applicable to your artificial intelligence project. Deep learning can perform well on both small amounts of data and in situations where human subject matter experts can support the performance of various tasks, including feature extraction. In addition to its versatility, deep learning offers users abundant flexibility and ease of use, making it appealing for many business applications that face resource limitations or other constraints.
There are numerous benefits to using deep learning over traditional machine learning. One major advantage of deep learning is the ability to automatically and effectively identify features in large volumes of data. This allows organizations to complete many more complex tasks than they were able to before (e.g., voice and image recognition). Organizations now have the opportunity to develop cutting-edge technologies through leveraging the exceptional capability of deep learning to model high-level abstractions and process unstructured data.
By leveraging the unique capabilities of machine learning techniques, organizations can create AI systems that are not only more productive but also specifically designed to meet their individual project requirements.
Knowing when to utilize machine learning and/or deep learning for multiple project types (i.e. detecting fraudulent transactions; developing autonomous vehicles), will ultimately lead to greater success in achieving your project goals.
In summary, while machine learning and deep learning share similarities, they differ significantly. Therefore, choosing the correct method(s) and tools for the specific application(s) you are interested in is critical as you venture into AI.
Q&A
Question: What is the primary difference between machine learning and deep learning? Answer: The primary distinction between deep learning and machine learning is the way each method approaches data. Deep learning models use a type of artificial network called a multi-layered neural network (with many layers) to learn the characteristics of larger datasets automatically. Machine learning methods rely on manually engineered, feature-based algorithms that are trained on features extracted from smaller data sets. This makes machine learning suitable for tasks like predictive modeling and classification. In contrast, deep learning is better suited to complex problems, such as image and speech recognition, as well as natural language processing.
Question: How does supervised learning differ from unsupervised learning? Answer: Supervised Learning is when you give your Model Labeled Data, and it learns to match what’s in the Input with what’s in the Output. Unsupervised Learning is when you give your Model Raw Data (no labels), and it learns to find Patterns or Groupings on its own. That means that the Model doesn’t know anything about the Outcome.
Question: When do I use machine learning instead of deep learning? Answer: You will want to use machine learning in cases where you have a limited number of samples, or if you have domain knowledge about your data that allows you to create meaningful features through feature engineering. In addition, you would want to use machine learning when interpretability (you need to understand how your model works), training speed, and minimal computing resources are key to your project.
Question: What are some typical applications of deep learning? Answer: Deep Learning has many application areas. Some examples include Computer Vision (e.g., facial recognition, object detection), Natural Language Processing (e.g., language translation, chatbots), and Audio Recognition (e.g., voice commands, speech-to-text).
Question: What role does data volume play in the effectiveness of machine learning and deep learning? Answer: Data Volume plays a critical role in Machine Learning & Deep Learning success. Machine Learning can be successful with smaller or medium-sized datasets and manual feature selection. However, Deep Learning is most successful when large amounts of data exist. It enables the automatic extraction of feature sets that may have been difficult or time-consuming to identify, and it supports the learning of complex patterns in the data; this will lead to better results as more data are input into the system.







{kind=link}